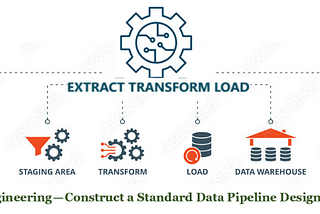
PinnedRyan ArjunData Engineering — Construct a Standard Data Pipeline Design PatternOne common challenges encountered by developers and data professionals in the area of data processing and analysis is whether to import…Nov 3, 2023Nov 3, 2023
Ryan ArjunPySpark — Replace Accented letters with their Non-Accented lettersIn this tutorial, you will learn “How to Replace Accented letters with their non accented letters By Using PySpark” in DataBricks. For…Jun 26Jun 26
Ryan ArjunDataBricks — How to Find Out Returning Customers within 7 days in PySpark DataframePySpark is a Python API for Apache Spark, whereas Apache Spark is an Analytical Processing Engine for large scale sophisticated…Jun 5Jun 5
Ryan ArjunOrchestration- Databricks Workflow VS Azure Data FactoryIdeally, Databricks Workflow orchestrates and schedules Databricks notebooks within the Databricks environment, whereas Azure Data Factory…May 21May 21
Ryan ArjunWant to become a Data Engineer?Sharing the list of complete topics and subtopics of python for Data Engineers:May 15May 15
Ryan ArjunIn what cases CTEs will perform better than intermediate tables ?As we all know, CTEs are a useful SQL feature that can help you design cleaner, more maintainable queries and better handle recursive data…May 15May 15
Ryan ArjunSnowflake — Top 25 Highly Recommended Interview QuestionsSnowflake is a cloud-based data warehousing technology that enables the scalable and safe storing and processing of structured and…Apr 28Apr 28
Ryan ArjunTSQL — Sending Email in HTML Table Format in SQL ServerAs we know that SQL language is specified as an ANSI and ISO standard and performance, scalability, and optimisation are important for…Apr 25Apr 25
Ryan ArjunPySpark — Top 5 Optimization TechniquesIf you are working as a PySpark or Python developer in any Data Engineering stack on a very huge data process then Optimizing PySpark jobs…Mar 28Mar 28
Ryan ArjunScala — How to Calculate Running Total Or Accumulative Sum in DataBricksIn this tutorial, you will learn “How to calculate Running Total Or Accumulative Sum by using Scala” in DataBricks.Mar 3Mar 3